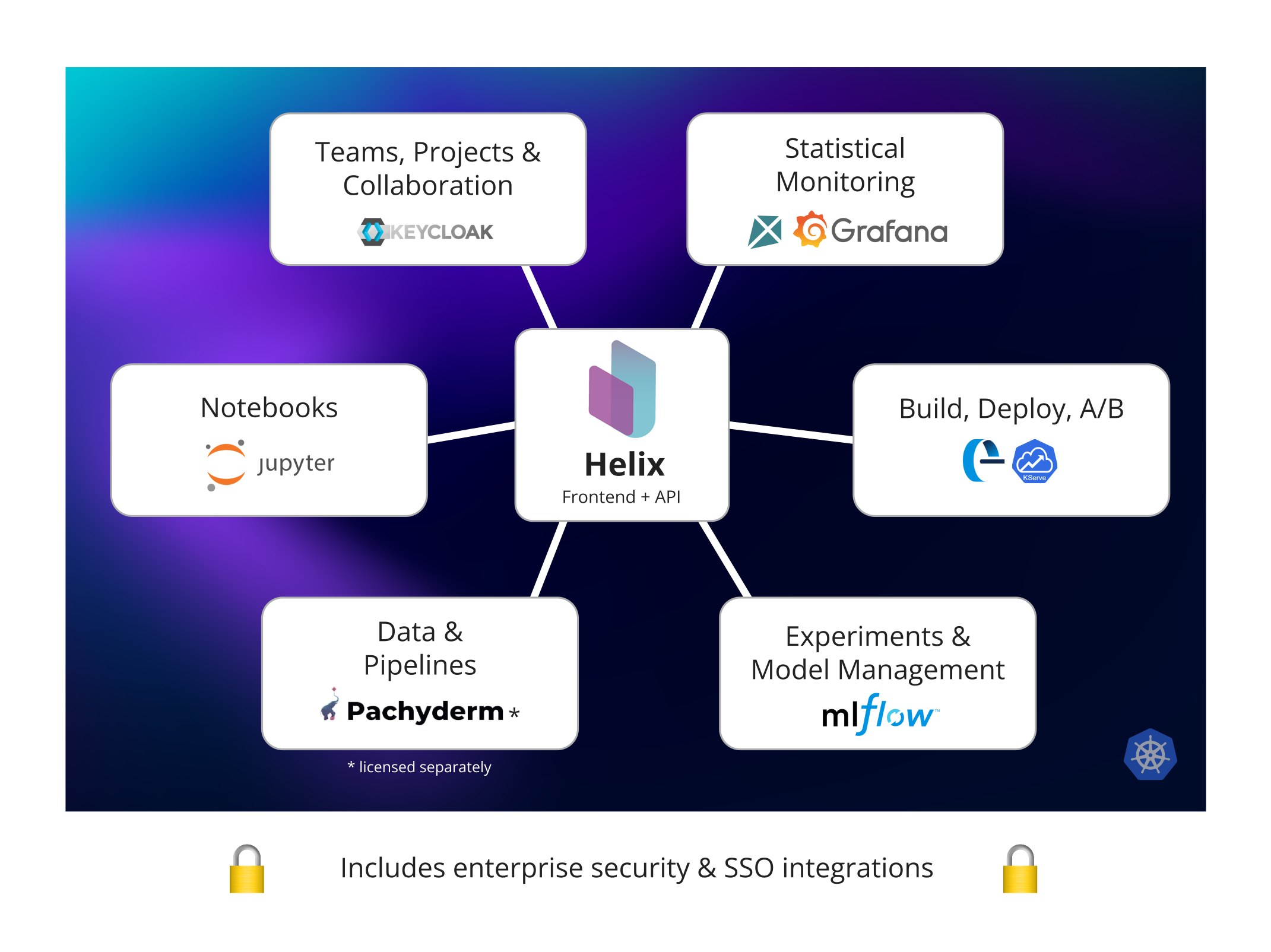
Helix takes the best open source MLOps components and integrates them in an enterprise-ready, supported and secure experience so that your data science and ML teams can be productive immediately within a robust governance framework.
Because it stands on the shoulders of giants, Helix itself is small, lightweight yet surprisingly powerful. It is a hosted control plane that and can be used to easily to integrate existing systems and/or create an MLOps platform in your own cloud account from scratch.